24 KiB
| stage | group | info |
|---|---|---|
| none | unassigned | To determine the technical writer assigned to the Stage/Group associated with this page, see https://about.gitlab.com/handbook/engineering/ux/technical-writing/#assignments |
Review Apps
Review Apps are deployed using the start-review-app-pipeline job. This job triggers a child pipeline containing a series of jobs to perform the various tasks needed to deploy a Review App.
For any of the following scenarios, the start-review-app-pipeline job would be automatically started:
- for merge requests with CI config changes
- for merge requests with frontend changes
- for merge requests with changes to
{,ee/,jh/}{app/controllers}/**/* - for merge requests with changes to
{,ee/,jh/}{app/models}/**/* - for merge requests with QA changes
- for scheduled pipelines
- the MR has the
pipeline:run-review-applabel set
QA runs on Review Apps
On every pipeline in the qa stage (which comes after the
review stage), the review-qa-smoke and review-qa-reliable jobs are automatically started. The review-qa-smoke runs
the QA smoke suite and the review-qa-reliable executes E2E tests identified as reliable.
You can also manually start the review-qa-all: it runs the full QA suite.
After the end-to-end test runs have finished, Allure reports are generated and published by
the allure-report-qa-smoke, allure-report-qa-reliable, and allure-report-qa-all jobs. A comment with links to the reports are added to the merge request.
Errors can be found in the gitlab-review-apps Sentry project and filterable by Review App URL or commit SHA.
Performance Metrics
On every pipeline in the qa stage, the
review-performance job is automatically started: this job does basic
browser performance testing using a
Sitespeed.io Container.
Sample Data for Review Apps
Upon deployment of a review app, project data is created from the sample-gitlab-project template project. This aims to provide projects with prepopulated resources to facilitate manual and exploratory testing.
The sample projects will be created in the root user namespace and can be accessed from the personal projects list for that user.
How to
Redeploy Review App from a clean slate
To reset Review App and redeploy from a clean slate, do the following:
- Run
review-stopjob. - Re-deploy by running or retrying
review-deployjob.
Doing this will remove all existing data from a previously deployed Review App.
Get access to the GCP Review Apps cluster
You need to open an access request (internal link)
for the gcp-review-apps-dev GCP group and role.
This grants you the following permissions for:
- Retrieving pod logs. Granted by Viewer (
roles/viewer). - Running a Rails console. Granted by Kubernetes Engine Developer (
roles/container.pods.exec).
Log into my Review App
For GitLab Team Members only. If you want to sign in to the review app, review the GitLab handbook information for the shared 1Password account.
- The default username is
root. - The password can be found in the 1Password login item named
GitLab EE Review App.
Enable a feature flag for my Review App
- Open your Review App and log in as documented above.
- Create a personal access token.
- Enable the feature flag using the Feature flag API.
Find my Review App slug
- Open the
review-deployjob. - Look for
** Deploying review-*. - For instance for
** Deploying review-1234-abc-defg... **, your Review App slug would bereview-1234-abc-defgin this case.
Run a Rails console
- Make sure you have access to the cluster and the
container.pods.execpermission first. - Filter Workloads by your Review App slug. For example,
review-qa-raise-e-12chm0. - Find and open the
toolboxDeployment. For example,review-qa-raise-e-12chm0-toolbox. - Click on the Pod in the "Managed pods" section. For example,
review-qa-raise-e-12chm0-toolbox-d5455cc8-2lsvz. - Click on the
KUBECTLdropdown, thenExec->toolbox. - Replace
-c toolbox -- lswith-it -- gitlab-rails consolefrom the default command or- Run
kubectl exec --namespace review-qa-raise-e-12chm0 review-qa-raise-e-12chm0-toolbox-d5455cc8-2lsvz -it -- gitlab-rails consoleand- Replace
review-qa-raise-e-12chm0-toolbox-d5455cc8-2lsvzwith your Pod's name.
- Replace
- Run
Dig into a Pod's logs
- Make sure you have access to the cluster and the
container.pods.getLogspermission first. - Filter Workloads by your Review App slug. For example,
review-qa-raise-e-12chm0. - Find and open the
migrationsDeployment. For example,review-qa-raise-e-12chm0-migrations.1. - Click on the Pod in the "Managed pods" section. For example,
review-qa-raise-e-12chm0-migrations.1-nqwtx. - Click on the
Container logslink.
Alternatively, you could use the Logs Explorer which provides more utility to search logs. An example query for a pod name is as follows:
resource.labels.pod_name:"review-qa-raise-e-12chm0-migrations"
How does it work?
CI/CD architecture diagram
graph TD
A["build-qa-image, compile-production-assets<br/>(canonical default refs only)"];
B[review-build-cng];
C[review-deploy];
D[CNG-mirror];
E[review-qa-smoke, review-qa-reliable];
A -->|once the `prepare` stage is done| B
B -.->|triggers a CNG-mirror pipeline and wait for it to be done| D
D -.->|polls until completed| B
B -->|once the `review-build-cng` job is done| C
C -->|once the `review-deploy` job is done| E
subgraph "1. gitlab `prepare` stage"
A
end
subgraph "2. gitlab `review-prepare` stage"
B
end
subgraph "3. gitlab `review` stage"
C["review-deploy<br><br>Helm deploys the Review App using the Cloud<br/>Native images built by the CNG-mirror pipeline.<br><br>Cloud Native images are deployed to the `review-apps`<br>Kubernetes (GKE) cluster, in the GCP `gitlab-review-apps` project."]
end
subgraph "4. gitlab `qa` stage"
E[review-qa-smoke, review-qa-reliable<br><br>gitlab-qa runs the smoke and reliable suites against the Review App.]
end
subgraph "CNG-mirror pipeline"
D>Cloud Native images are built];
end
Detailed explanation
- On every pipeline during the
preparestage, thecompile-production-assetsjob is automatically started.- Once it's done, the
review-build-cngjob starts since theCNG-mirrorpipeline triggered in the following step depends on it.
- Once it's done, the
- Once
compile-production-assetsis done, thereview-build-cngjob triggers a pipeline in theCNG-mirrorproject.- The
review-build-cngjob automatically starts only if your MR includes CI or frontend changes. In other cases, the job is manual. - The
CNG-mirrorpipeline creates the Docker images of each component (for example,gitlab-rails-ee,gitlab-shell,gitalyetc.) based on the commit from the GitLab pipeline and stores them in its registry. - We use the
CNG-mirrorproject so that theCNG, (Cloud Native GitLab), project's registry is not overloaded with a lot of transient Docker images. - Note that the official CNG images are built by the
cloud-native-imagejob, which runs only for tags, and triggers itself aCNGpipeline.
- The
- Once
review-build-cngis done, thereview-deployjob deploys the Review App using the official GitLab Helm chart to thereview-appsKubernetes cluster on GCP.- The actual scripts used to deploy the Review App can be found at
scripts/review_apps/review-apps.sh. - These scripts are basically
our official Auto DevOps scripts where the
default CNG images are overridden with the images built and stored in the
CNG-mirrorproject's registry. - Since we're using the official GitLab Helm chart, this means you get a dedicated environment for your branch that's very close to what it would look in production.
- Each review app is deployed to its own Kubernetes namespace. The namespace is based on the Review App slug that is unique to each branch.
- The actual scripts used to deploy the Review App can be found at
- Once the
review-deployjob succeeds, you should be able to use your Review App thanks to the direct link to it from the MR widget. To log into the Review App, see "Log into my Review App?" below.
Additional notes:
- If the
review-deployjob keeps failing (and a manual retry didn't help), please post a message in the#g_qe_engineering_productivitychannel and/or create a~"Engineering Productivity"~"ep::review apps"~"type::bug"issue with a link to your merge request. Note that the deployment failure can reveal an actual problem introduced in your merge request (that is, this isn't necessarily a transient failure)! - If the
review-qa-smokeorreview-qa-reliablejob keeps failing (note that we already retry them once), please check the job's logs: you could discover an actual problem introduced in your merge request. You can also download the artifacts to see screenshots of the page at the time the failures occurred. If you don't find the cause of the failure or if it seems unrelated to your change, please post a message in the#qualitychannel and/or create a ~Quality ~"type::bug" issue with a link to your merge request. - The manual
review-stopcan be used to stop a Review App manually, and is also started by GitLab once a merge request's branch is deleted after being merged. - The Kubernetes cluster is connected to the
gitlabprojects using the GitLab Kubernetes integration. This basically allows to have a link to the Review App directly from the merge request widget.
Auto-stopping of Review Apps
Review Apps are automatically stopped 2 days after the last deployment thanks to the Environment auto-stop feature.
If you need your Review App to stay up for a longer time, you can
pin its environment or retry the
review-deploy job to update the "latest deployed at" time.
The review-cleanup job that automatically runs in scheduled
pipelines (and is manual in merge request) stops stale Review Apps after 5 days,
deletes their environment after 6 days, and cleans up any dangling Helm releases
and Kubernetes resources after 7 days.
The review-gcp-cleanup job that automatically runs in scheduled pipelines
(and is manual in merge request) removes any dangling GCP network resources
that were not removed along with the Kubernetes resources.
Cluster configuration
The cluster is configured via Terraform in the engineering-productivity-infrastructure project.
Node pool image type must be Container-Optimized OS (cos), not Container-Optimized OS with Containerd (cos_containerd),
due to this known issue on the Kubernetes executor for GitLab Runner
Helm
The Helm version used is defined in the
registry.gitlab.com/gitlab-org/gitlab-build-images:gitlab-helm3-kubectl1.14 image
used by the review-deploy and review-stop jobs.
Diagnosing unhealthy Review App releases
If Review App Stability
dips this may be a signal that the review-apps cluster is unhealthy.
Leading indicators may be health check failures leading to restarts or majority failure for Review App deployments.
The Review Apps Overview dashboard aids in identifying load spikes on the cluster, and if nodes are problematic or the entire cluster is trending towards unhealthy.
Database related errors in review-deploy, review-qa-smoke, or review-qa-reliable
Occasionally the state of a Review App's database could diverge from the database schema. This could be caused by changes to migration files or schema, such as a migration being renamed or deleted. This typically manifests in migration errors such as:
- migration job failing with a column that already exists
- migration job failing with a column that does not exist
To recover from this, please attempt to redeploy Review App from a clean slate
Release failed with ImagePullBackOff
Potential cause:
If you see an ImagePullBackoff status, check for a missing Docker image.
Where to look for further debugging:
To check that the Docker images were created, run the following Docker command:
`DOCKER_CLI_EXPERIMENTAL=enabled docker manifest repository:tag`
The output of this command indicates if the Docker image exists. For example:
DOCKER_CLI_EXPERIMENTAL=enabled docker manifest inspect registry.gitlab.com/gitlab-org/build/cng-mirror/gitlab-rails-ee:39467-allow-a-release-s-associated-milestones-to-be-edited-thro
If the Docker image does not exist:
- Verify the
image.repositoryandimage.tagoptions in thehelm upgrade --installcommand match the repository names used by CNG-mirror pipeline. - Look further in the corresponding downstream CNG-mirror pipeline in
review-build-cngjob.
Node count is always increasing (never stabilizing or decreasing)
Potential cause:
That could be a sign that the review-cleanup job is
failing to cleanup stale Review Apps and Kubernetes resources.
Where to look for further debugging:
Look at the latest review-cleanup job log, and identify look for any
unexpected failure.
p99 CPU utilization is at 100% for most of the nodes and/or many components
Potential cause:
This could be a sign that Helm is failing to deploy Review Apps. When Helm has a
lot of FAILED releases, it seems that the CPU utilization is increasing, probably
due to Helm or Kubernetes trying to recreate the components.
Where to look for further debugging:
Look at a recent review-deploy job log.
Useful commands:
# Identify if node spikes are common or load on specific nodes which may get rebalanced by the Kubernetes scheduler
kubectl top nodes | sort --key 3 --numeric
# Identify pods under heavy CPU load
kubectl top pods | sort --key 2 --numeric
The logging/user/events/FailedMount chart is going up
Potential cause:
This could be a sign that there are too many stale secrets and/or configuration maps.
Where to look for further debugging:
Look at the list of Configurations
or kubectl get secret,cm --sort-by='{.metadata.creationTimestamp}' | grep 'review-'.
Any secrets or configuration maps older than 5 days are suspect and should be deleted.
Useful commands:
# List secrets and config maps ordered by created date
kubectl get secret,cm --sort-by='{.metadata.creationTimestamp}' | grep 'review-'
# Delete all secrets that are 5 to 9 days old
kubectl get secret --sort-by='{.metadata.creationTimestamp}' | grep '^review-' | grep '[5-9]d$' | cut -d' ' -f1 | xargs kubectl delete secret
# Delete all secrets that are 10 to 99 days old
kubectl get secret --sort-by='{.metadata.creationTimestamp}' | grep '^review-' | grep '[1-9][0-9]d$' | cut -d' ' -f1 | xargs kubectl delete secret
# Delete all config maps that are 5 to 9 days old
kubectl get cm --sort-by='{.metadata.creationTimestamp}' | grep 'review-' | grep -v 'dns-gitlab-review-app' | grep '[5-9]d$' | cut -d' ' -f1 | xargs kubectl delete cm
# Delete all config maps that are 10 to 99 days old
kubectl get cm --sort-by='{.metadata.creationTimestamp}' | grep 'review-' | grep -v 'dns-gitlab-review-app' | grep '[1-9][0-9]d$' | cut -d' ' -f1 | xargs kubectl delete cm
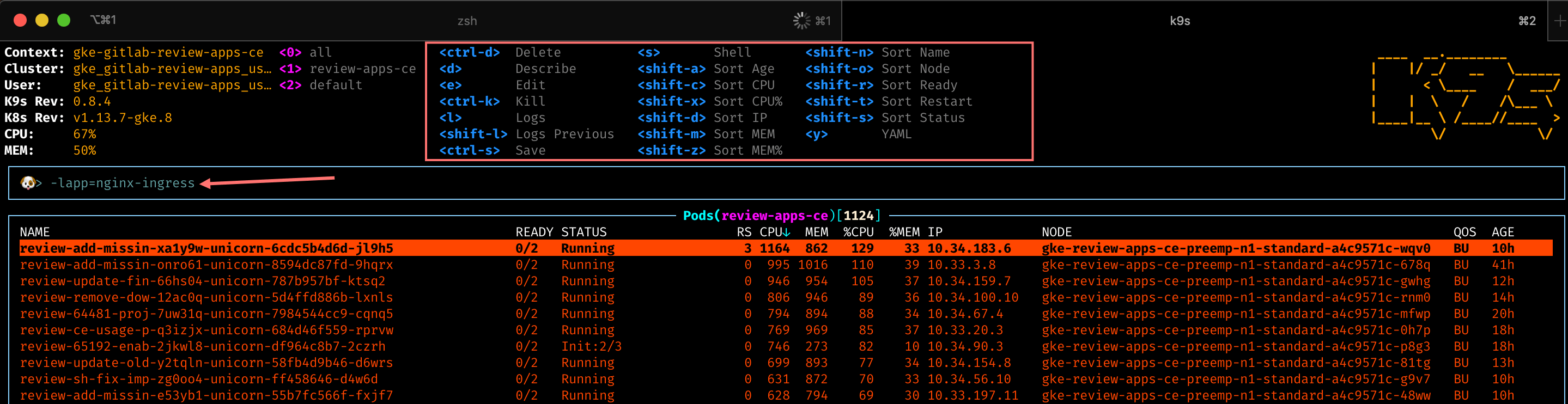
Using K9s
K9s is a powerful command line dashboard which allows you to filter by labels. This can help identify trends with apps exceeding the review-app resource requests. Kubernetes schedules pods to nodes based on resource requests and allow for CPU usage up to the limits.
- In K9s you can sort or add filters by typing the
/character-lrelease=<review-app-slug>- filters down to all pods for a release. This aids in determining what is having issues in a single deployment-lapp=<app>- filters down to all pods for a specific app. This aids in determining resource usage by app.
- You can scroll to a Kubernetes resource and hit
d(describe),s(shell),l(logs) for a deeper inspection
Troubleshoot a pending dns-gitlab-review-app-external-dns Deployment
Finding the problem
In the past, it happened
that the dns-gitlab-review-app-external-dns Deployment was in a pending state,
effectively preventing all the Review Apps from getting a DNS record assigned,
making them unreachable via domain name.
This in turn prevented other components of the Review App to properly start
(for example, gitlab-runner).
After some digging, we found that new mounts fail when performed
with transient scopes (for example, pods) of systemd-mount:
MountVolume.SetUp failed for volume "dns-gitlab-review-app-external-dns-token-sj5jm" : mount failed: exit status 1
Mounting command: systemd-run
Mounting arguments: --description=Kubernetes transient mount for /var/lib/kubelet/pods/06add1c3-87b4-11e9-80a9-42010a800107/volumes/kubernetes.io~secret/dns-gitlab-review-app-external-dns-token-sj5jm --scope -- mount -t tmpfs tmpfs /var/lib/kubelet/pods/06add1c3-87b4-11e9-80a9-42010a800107/volumes/kubernetes.io~secret/dns-gitlab-review-app-external-dns-token-sj5jm
Output: Failed to start transient scope unit: Connection timed out
This probably happened because the GitLab chart creates 67 resources, leading to a lot of mount points being created on the underlying GCP node.
The underlying issue seems to be a systemd bug
that was fixed in systemd v237. Unfortunately, our GCP nodes are currently
using v232.
For the record, the debugging steps to find out this issue were:
- Switch kubectl context to
review-apps-ce(we recommend usingkubectx) kubectl get pods | grep dnskubectl describe pod <pod name>& confirm exact error message- Web search for exact error message, following rabbit hole to a relevant Kubernetes bug report
- Access the node over SSH via the GCP console (Computer Engine > VM
instances then click the "SSH" button for the node where the
dns-gitlab-review-app-external-dnspod runs) - In the node:
systemctl --version=>systemd 232 - Gather some more information:
mount | grep kube | wc -l(returns a count, for example, 290)systemctl list-units --all | grep -i var-lib-kube | wc -l(returns a count, for example, 142)
- Check how many pods are in a bad state:
- Get all pods running a given node:
kubectl get pods --field-selector=spec.nodeName=NODE_NAME - Get all the
Runningpods on a given node:kubectl get pods --field-selector=spec.nodeName=NODE_NAME | grep Running - Get all the pods in a bad state on a given node:
kubectl get pods --field-selector=spec.nodeName=NODE_NAME | grep -v 'Running' | grep -v 'Completed'
- Get all pods running a given node:
Solving the problem
To resolve the problem, we needed to (forcibly) drain some nodes:
- Try a normal drain on the node where the
dns-gitlab-review-app-external-dnspod runs so that Kubernetes automatically move it to another node:kubectl drain NODE_NAME - If that doesn't work, you can also perform a forcible "drain" the node by removing all pods:
kubectl delete pods --field-selector=spec.nodeName=NODE_NAME - In the node:
- Perform
systemctl daemon-reloadto remove the dead/inactive units - If that doesn't solve the problem, perform a hard reboot:
sudo systemctl reboot
- Perform
- Uncordon any cordoned nodes:
kubectl uncordon NODE_NAME
In parallel, since most Review Apps were in a broken state, we deleted them to
clean up the list of non-Running pods.
Following is a command to delete Review Apps based on their last deployment date
(current date was June 6th at the time) with
helm ls -d | grep "Jun 4" | cut -f1 | xargs helm delete --purge
Mitigation steps taken to avoid this problem in the future
We've created a new node pool with smaller machines to reduce the risk that a machine reaches the "too many mount points" problem in the future.
Frequently Asked Questions
Isn't it too much to trigger CNG image builds on every test run? This creates thousands of unused Docker images.
We have to start somewhere and improve later. Also, we're using the CNG-mirror project to store these Docker images so that we can just wipe out the registry at some point, and use a new fresh, empty one.
How do we secure this from abuse? Apps are open to the world so we need to find a way to limit it to only us.
This isn't enabled for forks.
Other resources
Helpful command line tools
- K9s - enables CLI dashboard across pods and enabling filtering by labels
- Stern - enables cross pod log tailing based on label/field selectors